Category Archives: Matching
Why is data cleansing important to companies?
The U.S. economy wastes an estimated $3 Trillion per year due to incorrect, inconsistent, fraudulent and redundant data. Businesses incur a very large portion of this cost. The Data Warehousing Institute estimate that the total cost to U.S. business more than $600 Billion a year from bad data alone. That is a very large cost that can easily be reduced by investing a much smaller amount of money earlier business data processing. No business is immune to financial loss from lost sales or extra expenses caused by incorrect data. However businesses are able to limit these losses through proper data cleansing.
The rule of 1:10:100 by W. Edwards Deming says that it takes $1 to verify a record when it is first entered, $10 to clean or deduplicate bad data after entry, and $100 per record if nothing is done to rectify a data issue. Part of this cost is incurred due to mail cost. The average company wastes $180,000 per year on direct mail that does not reach the intended recipient due to inaccurate data. Poorly marketed advertisements to incorrect demographics are another expense of having poor or out of date information.
The most common issues found due to data quality are duplicate and old records. Within one month of receiving customer data 2% becomes incorrect due to moving, death, marriage or divorce. If you are receiving data from an outside source, i.e. other departments, other businesses, these sources may not know how old the records are, if imported data is several months old 10% or more may be inaccurate. By having tools in house, companies can limit the level of incorrect data they deal with. An issues with in house data cleaning is that IT departments are often heavily relied on for that process. IT professionals have expert knowledge in technical issues, but often lack in-depth data processing best practices. Usually companies employ data analysis experts, but again, they often lack in-depth IT knowledge. The strength of utilizing business data is dependent on these professionals ability to function at their best. Often there is time lost or wasted due to lack of clear communication between these two departments. In addition lack of understanding causes incorrect information to be returned and can result in having to redo various aspects of the process.
What does Aim-Smart do to eliminate these issues? Aim-Smart is built with the business user, analysis expert and IT personal in mind. With Aim-Smart business users and analysis experts are able to manipulate data with the speed and accuracy of IT professionals and use their knowledge of advanced data processing techniques to remove or update data as needed. This is done all with in Excel, a comfortable environment for any business professional. This allows the IT professional to focus on the upkeep of the data platforms and focus on maintaining the platforms for data storage. I also removes many opportunities for misunderstanding and communication breakdown. It is estimated that up to 50% of IT expenses are spent on data cleaning. Aim-Smart removes most of the data cleaning process from the IT department. By putting the power of data cleaning in the hands of the business user, IT demands drop and allows the IT professionals to focus on strengthening and updating internal systems within the company. Aim-Smart allows business users to remove data, or update records they find to be out of date. It also allows them to manipulate the data as they want through parsing, standardization and other features. By doing this, company marketing budgets can more effectively be spent on contacts or data results that are accurate. This helps to maximize the use of company money spent on advertising as well as other expenses.
Source:
“$3 Trillion Problem: Three Best Practices for Today’s Dirty Data Pandemic” by Hollis Tibbetts
Improving Match Performance
When using Aim-Smart to match data, there are several steps you can do to improve performance.
First, when matching two sources, always make the second source (called the target) the larger of the two databases. The reason for this is that the sound-alike engine is applied only to Source A. There is processing time involved in creating each sound-alike, and additional time in storing them for matching later.
Second, if the target (source B) is greater than a few hundred thousand records, you may want to save the results to a Custom Database for use later. Thus, for any subsequent matches, performance is greatly improved. I have done extensive testing where source B had 3.5 million records and matching ran within minutes when source A had up to 10,000 records (to be precise 8 min 52 sec). To save the records to a custom database, use this feature when matching:
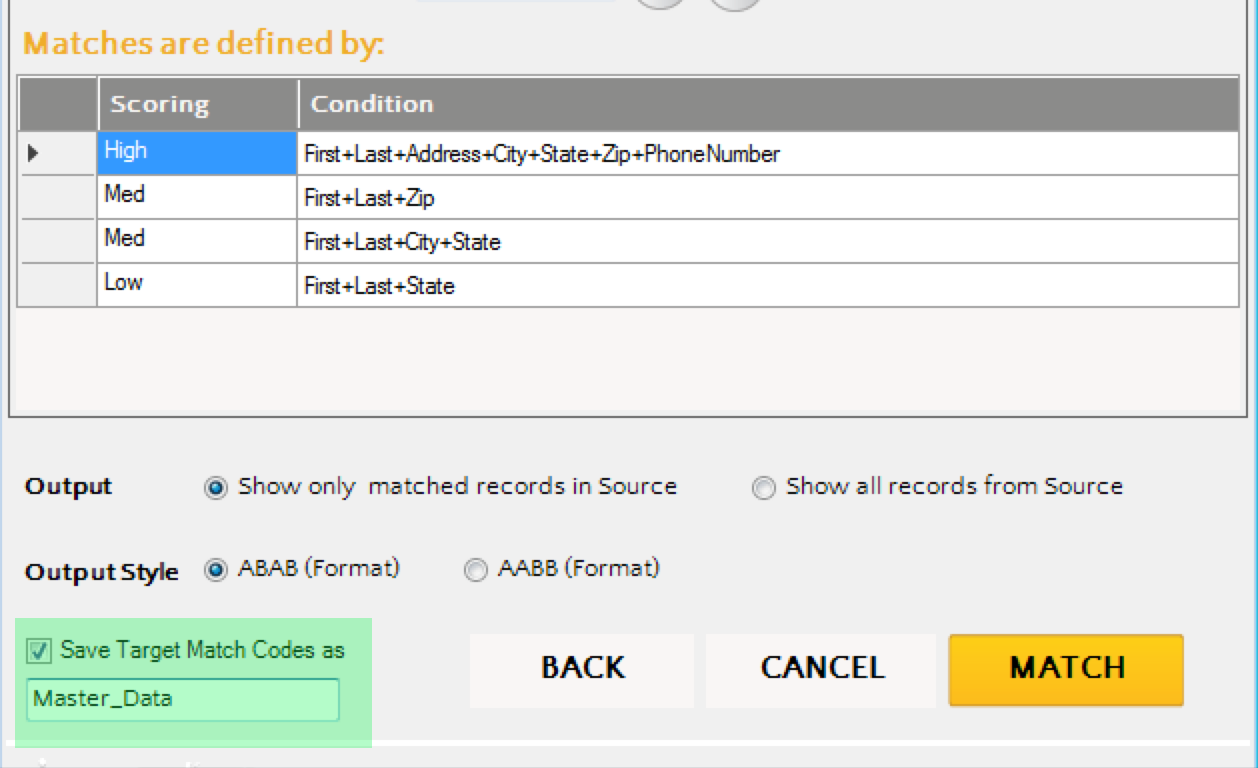
You can then reuse the “Master_Data” database by pressing the Custom DB Matching icon within the toolbar.
Third, each additional condition that is added, makes matching slightly slower. In my testing I found that going from one match condition to five increased processing time about 50%. You may not want nor be able to reduce the number of match conditions used, but something to keep in mind.
Lastly, use a solid state drive. 🙂 It’s amazing how much they improve I/O performance.
How to Smart Match Despite Data Quality Differences
One of the challenges matching involves inconsistent data quality between the sources involved in matching. Often times, users are trying to match one input against a “master” source, such as a CRM system, Master Data Management (MDM) system, etc. In these cases the master’s data quality is typically high. On the other hand, the input data source is often sporadically populated, and generally of poorer data quality.
Aim-Smart can obviously help identify the problems in the source data and also standardize the data in either source so that the formatting is consistent. The next issue is how to match data between the two sources given the differences in quality.
The input data source might look something like this:
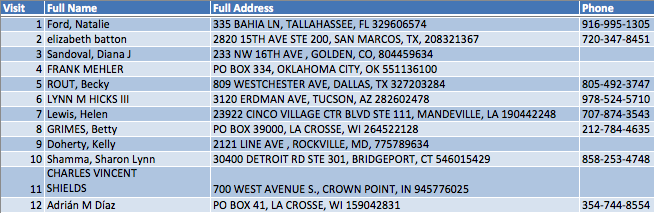
The MDM/CRM source might appear something more like:

We can use Aim-Smart to parse the full name and full address into more granular components so that it aligns more directly with our master source. After doing that it might look like this:

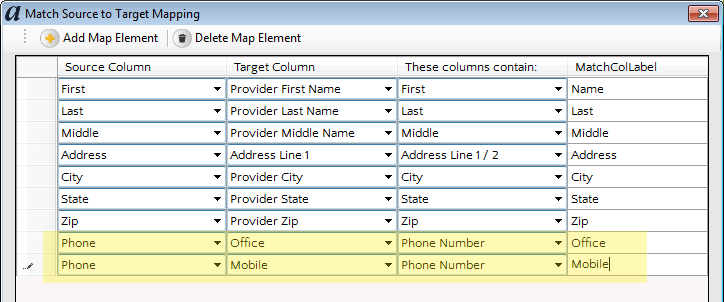
Note that while the master source had two different columns for phone number, the input source only has one. Furthermore, we don’t know if the input source is recording the office phone, the mobile phone, or perhaps a mixture of the two. Therefore, let’s map the fields as shown below – doing so will allow any phone number in the input source to match either the office or the mobile phone of the master.
I’ve found that the best way to overcome the differences in data quality between an input/master is to create a series of match rules that overlap each other. For example, given the data in these two sources, I might create a tiering of match rules that looks something like this:
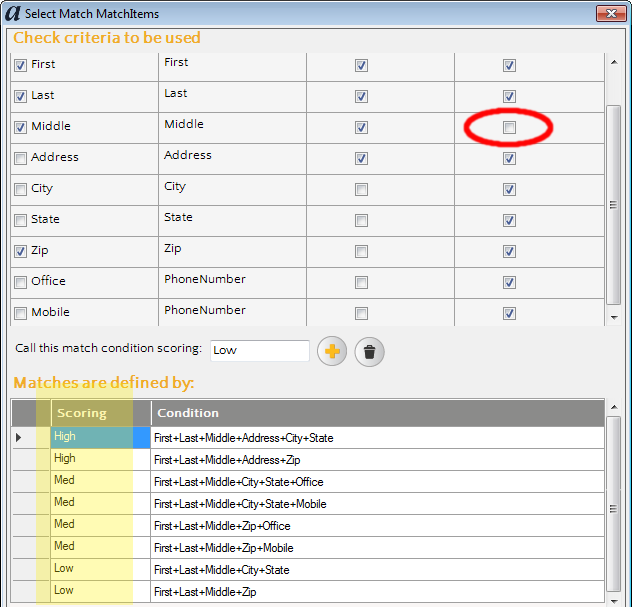
Note that the first and second “High” matches are similar. The first will search for matches using the address + zip whereas the second match will use address + city + state. Of course in theory the second rule won’t provide any new matches, I’ve found that it often does, especially in situations where a zip code is not known. The reverse is often true as well – someone may choose to specify their city as “Los Angeles” instead of “Monterey Park” because the former is easily recognized; thus the city won’t match but the zip code will.
Next, I want to point out that I have disabled the “Must Exist to Match” checkbox on middle name. What this means that records that are missing a middle name in either the input or the master, will still match each other; however, if a middle name is provided in both the input and the master, and they conflict with each other, the match will be broken. Thus, Victor A. Fehlberg matches Victor Fehlberg, but Victor A. Fehlberg does not match Victor B. Fehlberg. This same logic can be used with suffixes, etc. Suppose you want John Smith to match John Smith, Jr., but that you don’t want John Smith Sr. to match John Smith Jr. – you could use this same concept. In case you’re curious, here’s what the smart options looked like for middle name. In addition to enabling the component, I used one character so that John Albert Smith would match John A Smith.
Going back to my discussion on match rules, note that the “Medium” matches are defined to be a superset of the high matches. This is really helpful so that the lower quality matches can account for further data quality degradation or differences. When might this happen? A common scenario is when a person’s address in one system is the home address yet in the second system an office address is provided. Another scenario where this happens is when a person works at two addresses, e.g. a doctor that has an office but also works at the local hospital.
With match rules that cover a wide variety of data quality differences, and the ability to conditionally match a middle name (or suffix), you’ll find increased confidence in your match results. Happy matching!

What is Aim-Smart?
I am very excited to announce the launch of Aim-Smart – premier data processing software that leverages the latest in technology available. Founded in Denver, Colorado, Aim-Smart was created to change the way businesses view data management. Our company vision is to make data accessible to users at all levels throughout any company. Composed of experts in the field of data quality software, our team has numerous years of experience, programming, processing and working with data from the position of the user. Through our effort and vision we aim to innovate how business data quality software works.
Our signature product, Aim-Smart, an Excel add-in, allows users to Smart Match, Smart Parse and Smart Standardize data without relying on IT personnel or powerful servers. We know that when each individual within a company has immediate access to the data they need, performance of the entire company benefits. To maximize Smart Matching Aim-Smart utilizes fuzzy matching features; this allows for human inconsistencies, which are a constant challenge to accurate matching. In addition, Aim-Smart offers other features that facilitate the user in streamlining and sorting their data from different sources. These features, such as Genderize and Zap Gremlins, help by asserting to varying percentages the gender of customers based on name and remove difficult or unwanted characters from data, respectively. Aim-Smart was developed so that any business user can easily process data on their own computer, within the comfort of Excel, using this powerful plug-in.
 Accuracy is vitally important when dealing with data. Government agencies often change laws on what financial records need to be reported by a company. Issues occur when a company has different departments that function almost independently of one another. In these cases there are opportunities for miscommunication regarding payments going to, or being received from, outside individuals. Records often need to be compared and analyzed so that proper information can be reported. A high level of accuracy is required in these instances. Severe fines, or worse, can result when companies report incorrect information. This is why we at Aim-Smart are focused on delivering the highest level of accuracy for data matching.
Accuracy is vitally important when dealing with data. Government agencies often change laws on what financial records need to be reported by a company. Issues occur when a company has different departments that function almost independently of one another. In these cases there are opportunities for miscommunication regarding payments going to, or being received from, outside individuals. Records often need to be compared and analyzed so that proper information can be reported. A high level of accuracy is required in these instances. Severe fines, or worse, can result when companies report incorrect information. This is why we at Aim-Smart are focused on delivering the highest level of accuracy for data matching.
We understand that every person within a company can be more effective given the best-possible information. One issue that affects efficiency company-wide is not having the proper information when it is required. As an example, suppose Susan is testing several theories on how to increase exposure in different demographic areas. Waiting for Lilly, the systems analyst, (and possibly server availability) to get the job done will result in valuable time wasted, not to mention various discussions back and forth regarding exactly what’s needed. However, if Susan is able to access the data she needs and perform the data quality functions required without being forced to rely on Lilly, she can get her job done sooner and ultimately the company benefits. In order to bridge the divide between Susan and her data, Susan needs tools that she can work with without in-depth IT experience.
We are excited for every business to experience the power Aim-Smart brings to the individual business user. We are looking forward to helping all companies maximize time and resources in their companies. We are committed to be the best at what we do, and change the way businesses operate by increasing access to high quality data placed directly in the hands of the end users. Come experience Aim-Smart and feel the power of Data Quality Now.