Aim-Smart features
Deduplicate
When dealing with data from outside sources, users often encounter multiple records of the same entry. These records often need to be removed which can be difficult if the records aren’t exact matches. With Deduplicate Aim-Smart takes removing duplicate entries to a new level. While regular deduplication only removes exact matches Deduplicate uses intelligent fuzzy matching to show users other possible duplicates. Leveraging our advanced fuzzy logic technology Deduplicate is able to discern duplicates that aren’t exact matches. As an example if a file were to contain Jonathan Roberts, Jon Roberts and Jonathan B. Roberts Deduplicate is able to recognize that these are possibly the same record. In a new Excel sheet Deduplicate reports all the possible duplicates listed under the same “Cluster” number. This allows users to look through the duplicate matches to ensure that they are actually duplicates.
Here is a small list of different records that contain duplicates.
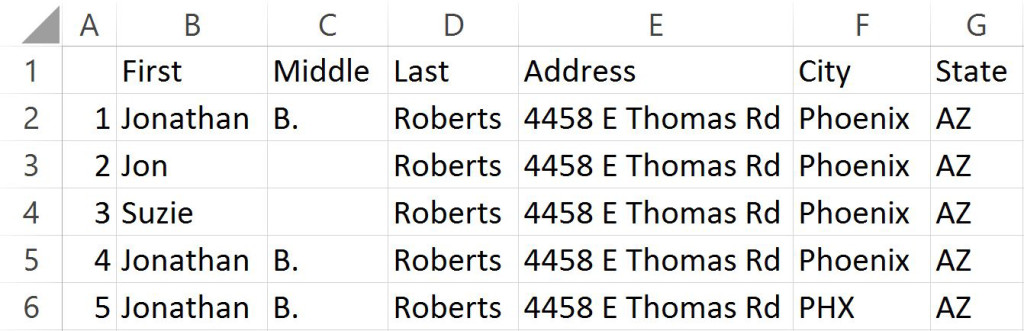
It is easy for us to see that four of these records are duplicates. It is far more complicated for computers to determine that though.
This is how Deduplicate is used:
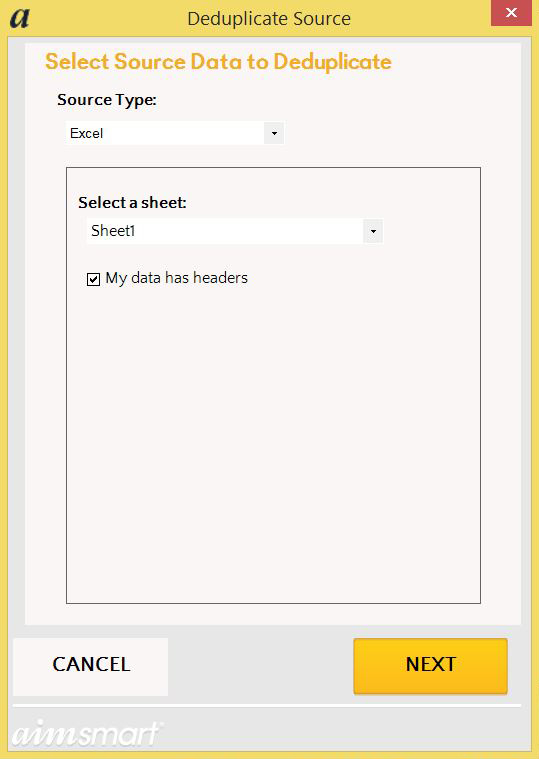
The Deduplicate Source window will be the first winow you’ll see after selecting Deduplicate. At this point users select their source for deduplication. Users can choose from an Excel worksheet, text file or database. For this example we are using an Excel spreadsheet.
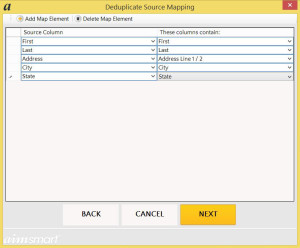
The next window users see is the Deduplicate Source Mapping window. Here users select the columns in the source and label the type of data each
After selecting and assigning data types to the columns being used for deduplication, Deduplicate allow users to choose multiple configurations of column usage as well as several Smart Match options to maximize access to possible duplicates. Here is an example of what a user might select for this data set.
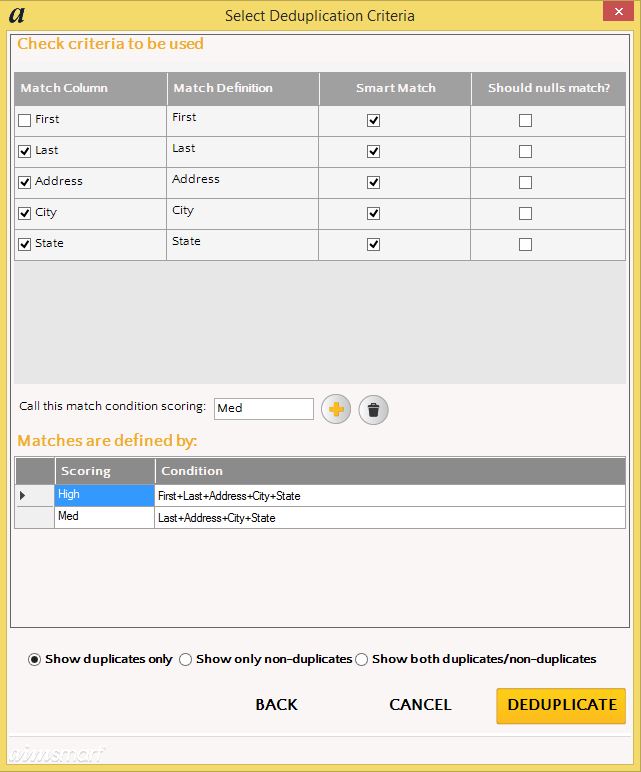
After applying the options above to the data provide these would be the results.
With these easy to read results users can determine the true duplicates from false positives. In addition users can see the number of possible duplicates giving a clearer overall picture of the quality of their data.