Category Archives: Parsing
Smart Parse and Smart Standardize Performance
Because Aim-Smart runs within Microsoft Excel, many people ask me how well Aim-Smart performs. I’ve written a blog about Smart Match performance, but today I’m sharing performance statistics on Smart Parse and Smart Standardize.
For the test, I used several sets of real US addresses, making test cases of 1, 10, 100… and up to 1 million records (close to the limits of Excel). You can see the results in the table below. I also graphed the results to show the linear behavior of the two functions.
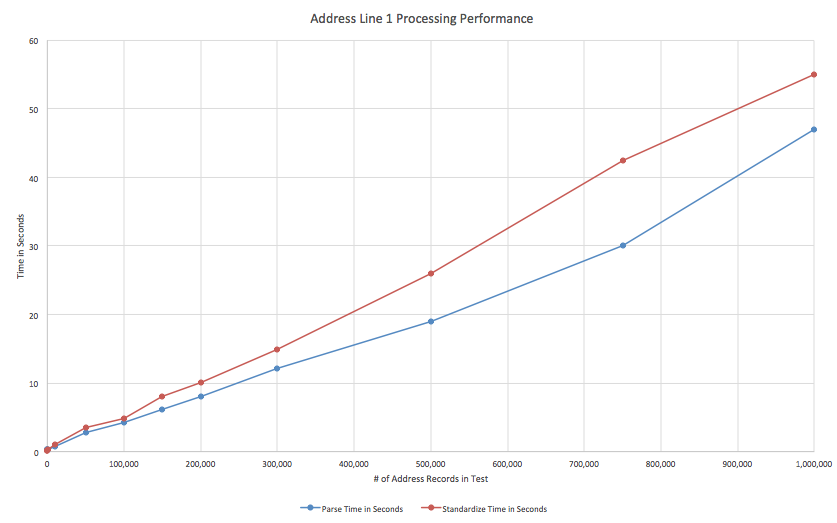
As you can see, performance is very, very good. As shown, Aim-Smart parses 1 million records in just 47 seconds. Smart Standardize runs on 1 million records in a similar time – 55 seconds.
I chose to parse and standardize address line 1 for this test because it is more complex than most data types (such as name or phone). Despite the additional complexity performance is still very nice.
The tests were performed on a Windows 8 laptop with 8GB of memory, an i7 Intel CPU (2.4Ghz) and a Samsung 850 EVO solid-state drive.
Although the laptop has several CPU cores, only one of them is used by the system at any given time, allowing the laptop to continue to be responsive – and therefore useful – for additional tasks such as checking email, etc.
Why accurate parsing is so important
When processing and matching data,  parsing is a fundamental necessity. Any weakness in parsing accuracy or ability will become immediately evident by dramatically lowering matching accuracy. The most effective data quality software programs will emphasize and implement parsing with an extremely high level of accuracy. Microsoft Excel is very familiar to most professionals, and can be an effective and easy way to keep track of large amounts of data. Although, without a strong Excel Add-In like Aim-Smart that data is very hard to parse into usable pieces or match once the data has been parsed in to usable pieces.
parsing is a fundamental necessity. Any weakness in parsing accuracy or ability will become immediately evident by dramatically lowering matching accuracy. The most effective data quality software programs will emphasize and implement parsing with an extremely high level of accuracy. Microsoft Excel is very familiar to most professionals, and can be an effective and easy way to keep track of large amounts of data. Although, without a strong Excel Add-In like Aim-Smart that data is very hard to parse into usable pieces or match once the data has been parsed in to usable pieces.
One of the challenges when parsing using computers is identifying what each piece of data represents. The human mind does this almost automatically. As an example when matching a name you can have several parts, like “Mr. Stephen A Johnston Esq.” but they may or may not be represented in possible matches. If users were trying to match “Mr. Stephen A Johnston Esq.” There are several formats it could be listed in. Possible listings could be, “Johnston, Stephen A”, “S Aaron Johnston Esq.”, “Mr. Stephen Arron Johnston” and many more. When a computer knows what each part of the full name is (i.e. title, first name, last name, suffix) it increases effectiveness greatly when looking for matches. Things as simple as recognizing that a title may or may not be present, or which word is a last name are necessities when a user needs accurate matches. The most common and effective way around this problem is to divide an entry in to the individual parts so that a user can assign the type of data to each part. Labeling and dividing these pieces is easy for an individual user when dealing with small numbers of entries, but when dealing with large lists of data it would take far too much time. This is where a computer capable of accurate parsing is so important.
While parsing is important for data storage.  Inaccurate parsing is ultimately no help at all when users want to match their parsed data. In order to implement the best quality of parsing the best software programs use several different processes to determine what to label each piece of data. There are multiple filters data may pass through before being assigned a label. These filters can be as simple as identifying if a piece of data only contains number or being compared to very specific lists of data for a match. Looking at an address we can see this possible issues first hand. 871 Thornton Pkwy, Ste. 109 for an example. A computer will not know how each number applies to an address. Through numerous filters the parsing software identifies if a number is the street number, unit number or street name. A well-built parsing program will then return the street address divided in to accurate categories. In the case of the earlier example it would return
Inaccurate parsing is ultimately no help at all when users want to match their parsed data. In order to implement the best quality of parsing the best software programs use several different processes to determine what to label each piece of data. There are multiple filters data may pass through before being assigned a label. These filters can be as simple as identifying if a piece of data only contains number or being compared to very specific lists of data for a match. Looking at an address we can see this possible issues first hand. 871 Thornton Pkwy, Ste. 109 for an example. A computer will not know how each number applies to an address. Through numerous filters the parsing software identifies if a number is the street number, unit number or street name. A well-built parsing program will then return the street address divided in to accurate categories. In the case of the earlier example it would return
Street Number: 871
Street Name: Thornton
Street Type: Pkwy
Unit Type: Ste
Unit Number: 109
This process ensures that a piece of data is labeled correctly. From that point on the data can be stored or matched with other data, matching accuracy is dramatically improved by having data parsed correctly.
In the end, parsing is important for different reasons. This is why accurate parsing is an important foundation for dealing with any amount of data.

What is Aim-Smart?
I am very excited to announce the launch of Aim-Smart – premier data processing software that leverages the latest in technology available. Founded in Denver, Colorado, Aim-Smart was created to change the way businesses view data management. Our company vision is to make data accessible to users at all levels throughout any company. Composed of experts in the field of data quality software, our team has numerous years of experience, programming, processing and working with data from the position of the user. Through our effort and vision we aim to innovate how business data quality software works.
Our signature product, Aim-Smart, an Excel add-in, allows users to Smart Match, Smart Parse and Smart Standardize data without relying on IT personnel or powerful servers. We know that when each individual within a company has immediate access to the data they need, performance of the entire company benefits. To maximize Smart Matching Aim-Smart utilizes fuzzy matching features; this allows for human inconsistencies, which are a constant challenge to accurate matching. In addition, Aim-Smart offers other features that facilitate the user in streamlining and sorting their data from different sources. These features, such as Genderize and Zap Gremlins, help by asserting to varying percentages the gender of customers based on name and remove difficult or unwanted characters from data, respectively. Aim-Smart was developed so that any business user can easily process data on their own computer, within the comfort of Excel, using this powerful plug-in.
 Accuracy is vitally important when dealing with data. Government agencies often change laws on what financial records need to be reported by a company. Issues occur when a company has different departments that function almost independently of one another. In these cases there are opportunities for miscommunication regarding payments going to, or being received from, outside individuals. Records often need to be compared and analyzed so that proper information can be reported. A high level of accuracy is required in these instances. Severe fines, or worse, can result when companies report incorrect information. This is why we at Aim-Smart are focused on delivering the highest level of accuracy for data matching.
Accuracy is vitally important when dealing with data. Government agencies often change laws on what financial records need to be reported by a company. Issues occur when a company has different departments that function almost independently of one another. In these cases there are opportunities for miscommunication regarding payments going to, or being received from, outside individuals. Records often need to be compared and analyzed so that proper information can be reported. A high level of accuracy is required in these instances. Severe fines, or worse, can result when companies report incorrect information. This is why we at Aim-Smart are focused on delivering the highest level of accuracy for data matching.
We understand that every person within a company can be more effective given the best-possible information. One issue that affects efficiency company-wide is not having the proper information when it is required. As an example, suppose Susan is testing several theories on how to increase exposure in different demographic areas. Waiting for Lilly, the systems analyst, (and possibly server availability) to get the job done will result in valuable time wasted, not to mention various discussions back and forth regarding exactly what’s needed. However, if Susan is able to access the data she needs and perform the data quality functions required without being forced to rely on Lilly, she can get her job done sooner and ultimately the company benefits. In order to bridge the divide between Susan and her data, Susan needs tools that she can work with without in-depth IT experience.
We are excited for every business to experience the power Aim-Smart brings to the individual business user. We are looking forward to helping all companies maximize time and resources in their companies. We are committed to be the best at what we do, and change the way businesses operate by increasing access to high quality data placed directly in the hands of the end users. Come experience Aim-Smart and feel the power of Data Quality Now.