Smart Parse and Smart Standardize Performance
Because Aim-Smart runs within Microsoft Excel, many people ask me how well Aim-Smart performs. I’ve written a blog about Smart Match performance, but today I’m sharing performance statistics on Smart Parse and Smart Standardize.
For the test, I used several sets of real US addresses, making test cases of 1, 10, 100… and up to 1 million records (close to the limits of Excel). You can see the results in the table below. I also graphed the results to show the linear behavior of the two functions.
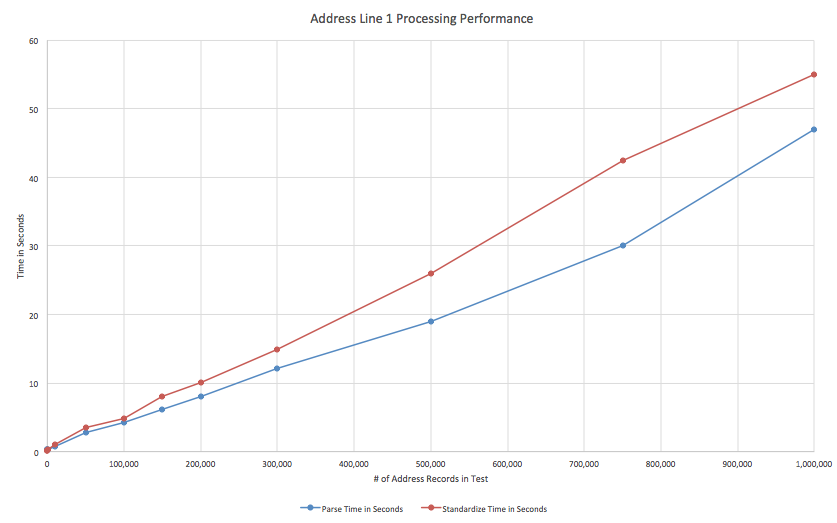
As you can see, performance is very, very good. As shown, Aim-Smart parses 1 million records in just 47 seconds. Smart Standardize runs on 1 million records in a similar time – 55 seconds.
I chose to parse and standardize address line 1 for this test because it is more complex than most data types (such as name or phone). Despite the additional complexity performance is still very nice.
The tests were performed on a Windows 8 laptop with 8GB of memory, an i7 Intel CPU (2.4Ghz) and a Samsung 850 EVO solid-state drive.
Although the laptop has several CPU cores, only one of them is used by the system at any given time, allowing the laptop to continue to be responsive – and therefore useful – for additional tasks such as checking email, etc.
How Deduplicate is Superior to Excel’s Remove Duplicates
Excel includes a standard duplicate removal tool called “Remove Duplicates”. I have used this tool before matching records using Smart Match (to avoid duplicate matching). While Remove Duplicates is useful, there are two fundamental issues to be aware of.
First, Remove Duplicates only removes exact matches within the Excel Sheet. On several occasions I’ve had two records that are the same, but because they come from different sources they aren’t exactly the same. One record may contain a contact with the name Anthony, but the same contact may be listed in another record as Tony. Remove Duplicates doesn’t give me any options for finding duplicates that aren’t exact matches.
The second issue I have with Remove Duplicates is the information it provides after removing the duplicates. The only information a user receives is the total number of removed records. Remove Duplicates won’t specify whether one record was duplicated several times or if several records were duplicated only once, or if there was some combination in between.
Deduplicate addresses these issues. When running Deduplicate I can access all the power of Aim-Smart’s matching logic, which allows for superior deduplication identification and reporting.
Here is an example of where Deduplicate results differ from Remove Duplicates. When using Remove Duplicates users have no ability to choose if duplicates are removed or not; in a way this isn’t a problem because every field matches exactly, so we know that we want the record removed. However, it leaves several possible duplicates (that vary by a small amount) untouched in the document. When using Deduplicate with the intelligent deduplicate logic we can see multiple sets of exact duplicates and we can see varying quality levels of other duplicates as well. This is useful when data may look like this.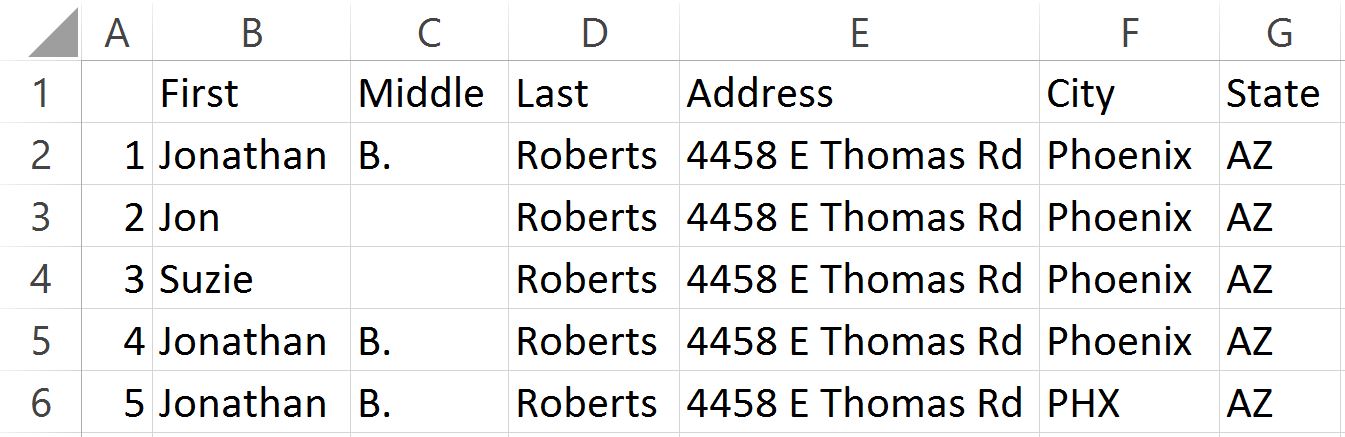
Using Remove Duplicates on all columns, with the data provided, would only remove row 4 and leave Rows 2 and 5, which are of course real duplicates. Remove Duplicates allows us to choose limited columns to compare. If a user chose a column subset (Last, Address, State) then rows 2-5 would be removed, but row 3 is not actually a duplicate. Without Aim-Smart’s Deduplicate tool it would take a lot of time and effort to identify (and potentially remove) the approximate match duplicates.
Deduplicate is different. Users can enter several different deduplication options at the same time. For the case above one option would be to create deduplication parameters like these.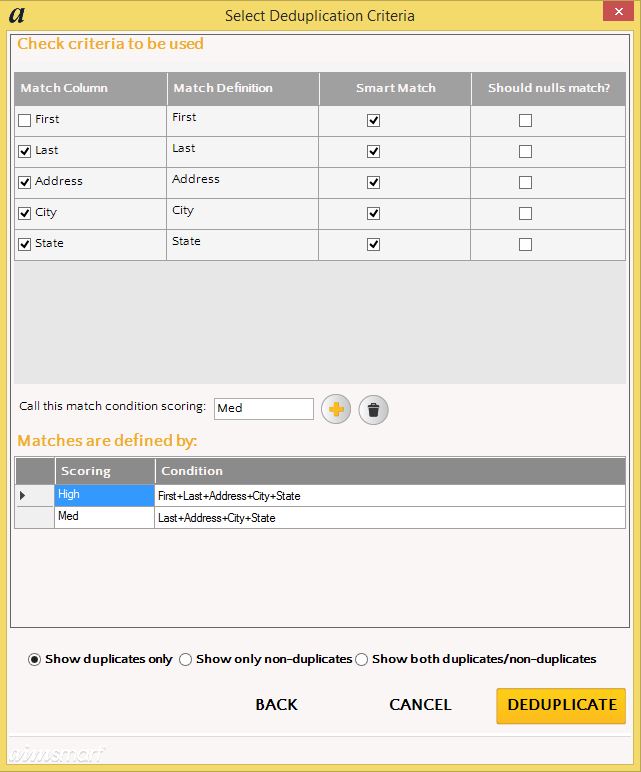
With the options shown above Deduplicate will return the following results.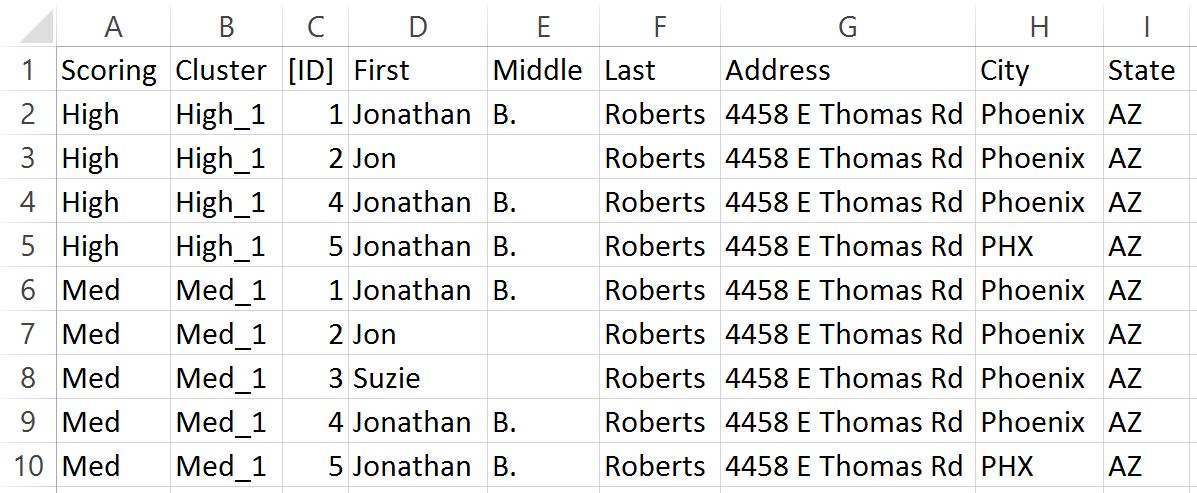
With these results a user is able to assess which matches are true matches and which ones aren’t true matches. The user then knows based on the [ID] which rows to remove in the original document. In addition users can easily see in the results how many duplicates each record group contains.
Thanks to these abilities and features Deduplicate is a more powerful tool than Excel’s Remove Duplicates tool.
Improving Match Performance
When using Aim-Smart to match data, there are several steps you can do to improve performance.
First, when matching two sources, always make the second source (called the target) the larger of the two databases. The reason for this is that the sound-alike engine is applied only to Source A. There is processing time involved in creating each sound-alike, and additional time in storing them for matching later.
Second, if the target (source B) is greater than a few hundred thousand records, you may want to save the results to a Custom Database for use later. Thus, for any subsequent matches, performance is greatly improved. I have done extensive testing where source B had 3.5 million records and matching ran within minutes when source A had up to 10,000 records (to be precise 8 min 52 sec). To save the records to a custom database, use this feature when matching:
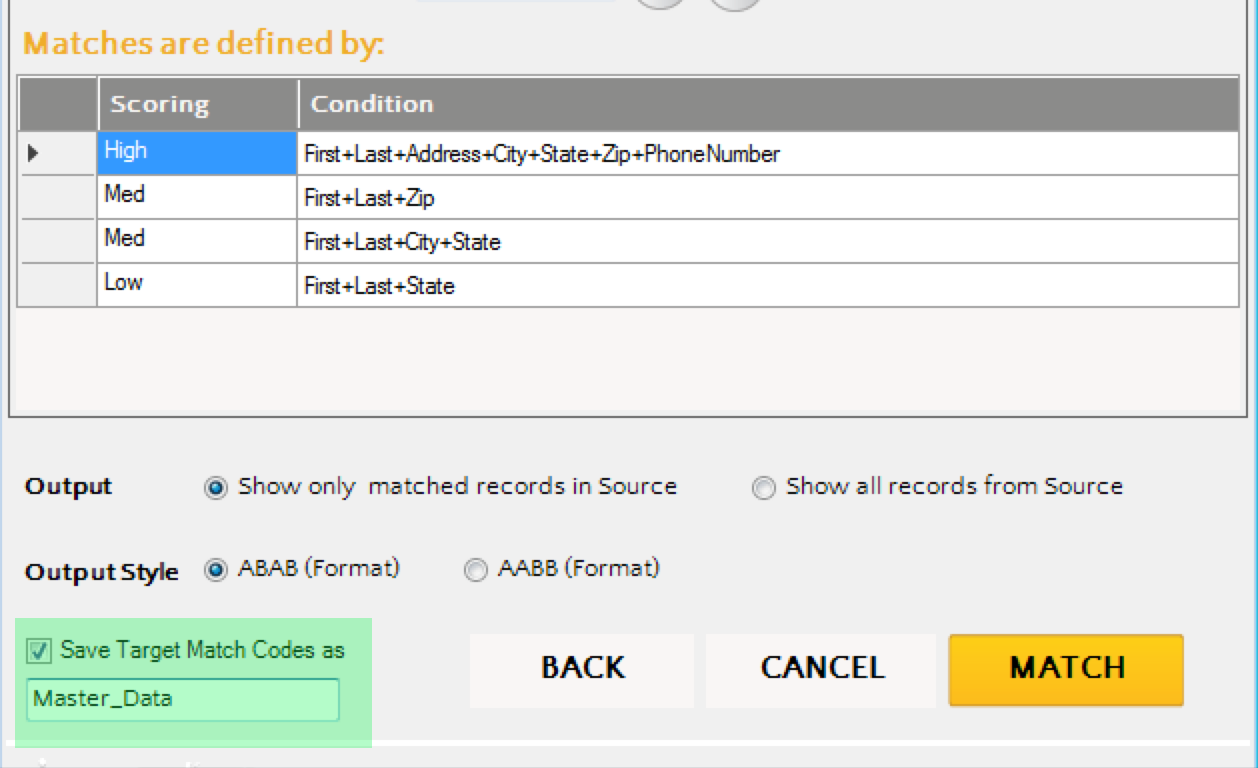
You can then reuse the “Master_Data” database by pressing the Custom DB Matching icon within the toolbar.
Third, each additional condition that is added, makes matching slightly slower. In my testing I found that going from one match condition to five increased processing time about 50%. You may not want nor be able to reduce the number of match conditions used, but something to keep in mind.
Lastly, use a solid state drive. 🙂 It’s amazing how much they improve I/O performance.