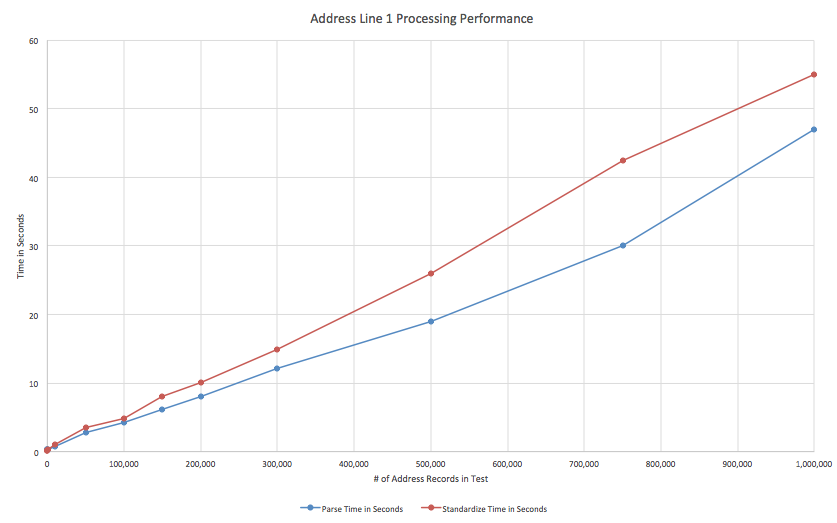
I’m happy to announce that Excel Address Verification is now available in the US! You can use it to easily ensure address deliverability, improve data quality, improve matching, and also certify your mail with CASS.
What is CASS?
USPS ZIP + 4®CASS™ certification avoids undeliverable mail resulting from bad or poor-quality addresses. Each year the US alone handles over 1.7 billion addresses that can’t be delivered because of missing data. The cost to the USPS is exorbitant – a jaw-dropping $159 million. Consequently, the US Postal Service implemented a program to incentivize companies to send only “good” mail.
USPS requires all CASS Certified™ vendors, such as Aim-Smart, to perform DPV and LACSLink processing when correcting an address. We do this work behind the scenes without requiring anything additional from the user.
What is DPV?
DPV ensures your mailing list has deliverable addresses. Whereas typical address correction processes only match an address to a range of valid addresses, DPV verifies that a mailing address is a known USPS delivery point.
To illustrate, suppose we had an address such as 456 Springfield Blvd. Standard address correction procedures might indicate that the address is valid, thereby assigning a Zip+4 value, when all the processor really did was make sure that 400-500 was a valid range for Springfield Blvd. In reality though, there might not be a 456 Springfield Blvd. This type of situation is avoided with DPV. Aim-Smart’s address verification for Excel will report back an error code and corresponding message indicating that the address is not deliverable.
What is LACSLink?
Many local governments are assigning new addresses to rural routes to improve the ability of emergency services (firefighters, police, etc.) to find addresses more quickly. You can imagine that it could be confusing to find an address like this one: 109506 County Road 1. As these addresses get renumbered, street names added, etc. it’s helpful for the USPS to have the updated address to deliver mail more efficiently. This is what LACSLink does – provide the lookup between the rural route address and its updated counterpart. As with DPV, this happens behind the scenes automatically for the user.
More information on DPV and LACSLink can be found at:
https://www.usps.com/business/manage-address-quality.htm
http://zip4.usps.com/ncsc/addressmgmt/dpv.htm
http://zip4.usps.com/ncsc/addressservices/addressqualityservices/lacsystem.htm