How to Smart Match Despite Data Quality Differences
One of the challenges matching involves inconsistent data quality between the sources involved in matching. Often times, users are trying to match one input against a “master” source, such as a CRM system, Master Data Management (MDM) system, etc. In these cases the master’s data quality is typically high. On the other hand, the input data source is often sporadically populated, and generally of poorer data quality.
Aim-Smart can obviously help identify the problems in the source data and also standardize the data in either source so that the formatting is consistent. The next issue is how to match data between the two sources given the differences in quality.
The input data source might look something like this:
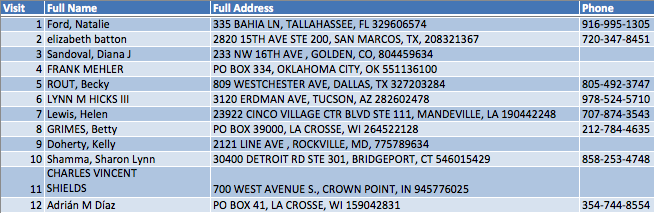
The MDM/CRM source might appear something more like:

We can use Aim-Smart to parse the full name and full address into more granular components so that it aligns more directly with our master source. After doing that it might look like this:

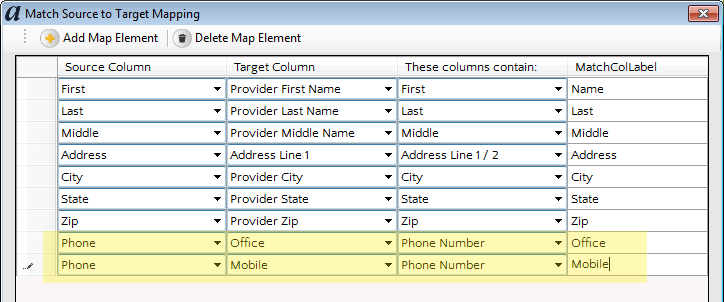
Note that while the master source had two different columns for phone number, the input source only has one. Furthermore, we don’t know if the input source is recording the office phone, the mobile phone, or perhaps a mixture of the two. Therefore, let’s map the fields as shown below – doing so will allow any phone number in the input source to match either the office or the mobile phone of the master.
I’ve found that the best way to overcome the differences in data quality between an input/master is to create a series of match rules that overlap each other. For example, given the data in these two sources, I might create a tiering of match rules that looks something like this:
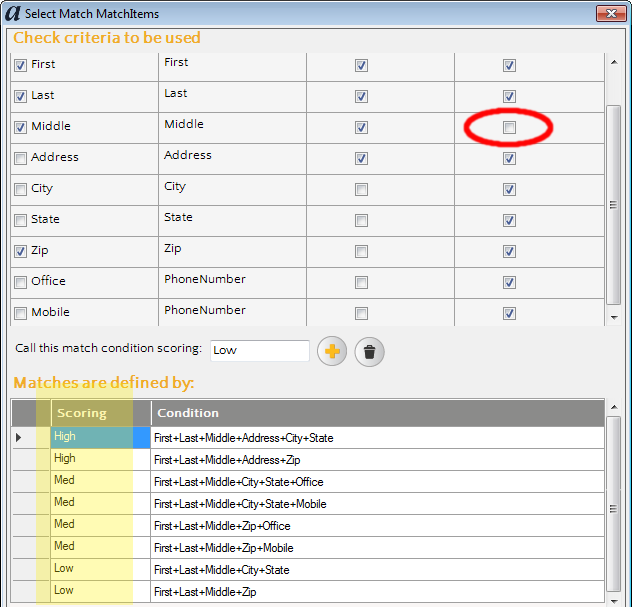
Note that the first and second “High” matches are similar. The first will search for matches using the address + zip whereas the second match will use address + city + state. Of course in theory the second rule won’t provide any new matches, I’ve found that it often does, especially in situations where a zip code is not known. The reverse is often true as well – someone may choose to specify their city as “Los Angeles” instead of “Monterey Park” because the former is easily recognized; thus the city won’t match but the zip code will.
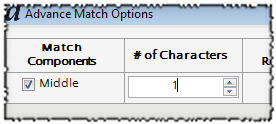
Next, I want to point out that I have disabled the “Must Exist to Match” checkbox on middle name. What this means that records that are missing a middle name in either the input or the master, will still match each other; however, if a middle name is provided in both the input and the master, and they conflict with each other, the match will be broken. Thus, Victor A. Fehlberg matches Victor Fehlberg, but Victor A. Fehlberg does not match Victor B. Fehlberg. This same logic can be used with suffixes, etc. Suppose you want John Smith to match John Smith, Jr., but that you don’t want John Smith Sr. to match John Smith Jr. – you could use this same concept. In case you’re curious, here’s what the smart options looked like for middle name. In addition to enabling the component, I used one character so that John Albert Smith would match John A Smith.
Going back to my discussion on match rules, note that the “Medium” matches are defined to be a superset of the high matches. This is really helpful so that the lower quality matches can account for further data quality degradation or differences. When might this happen? A common scenario is when a person’s address in one system is the home address yet in the second system an office address is provided. Another scenario where this happens is when a person works at two addresses, e.g. a doctor that has an office but also works at the local hospital.
With match rules that cover a wide variety of data quality differences, and the ability to conditionally match a middle name (or suffix), you’ll find increased confidence in your match results. Happy matching!